這系列的教學文章是
想讓大家省去如同機器人般的操作,把時間精力放在分析資料上面
 今天的學習要特別注意什麼?
今天的學習要特別注意什麼?一定要自己實作過一遍!
一定要自己實作過一遍!
一定要自己實作過一遍!
因為很重要所以要說三遍,前面幾篇文章比較偏向概念,但今後的文章概念實作並重;因為FB 與 IG 改版的速度極快,我現在提供的方法在他們改版後可能就會失效,所以文章的每個步驟要自己去實作才能理解為什麼這樣做,同時培養自己分析網頁結構的能力
 今日目標
今日目標1.1 拆解平常登入 FB 的步驟
1.2 將平常操作的位置轉化為程式可以讀懂的路徑(Xpath)
2.1 了解 selenium-webdriver 如何操作網頁元件
2.2 在 .env檔填上 FB 登入資訊,並從程式中讀取
2.3 讓爬蟲幫你完成平日登入的步驟
你可以想像 selenium-webdriver 這個套件就是讓機器人代替你的手來做操作,想要讓機器幫你操作,你需要告訴他明確的操作位置,接下來向大家介紹如何抓出這些位置
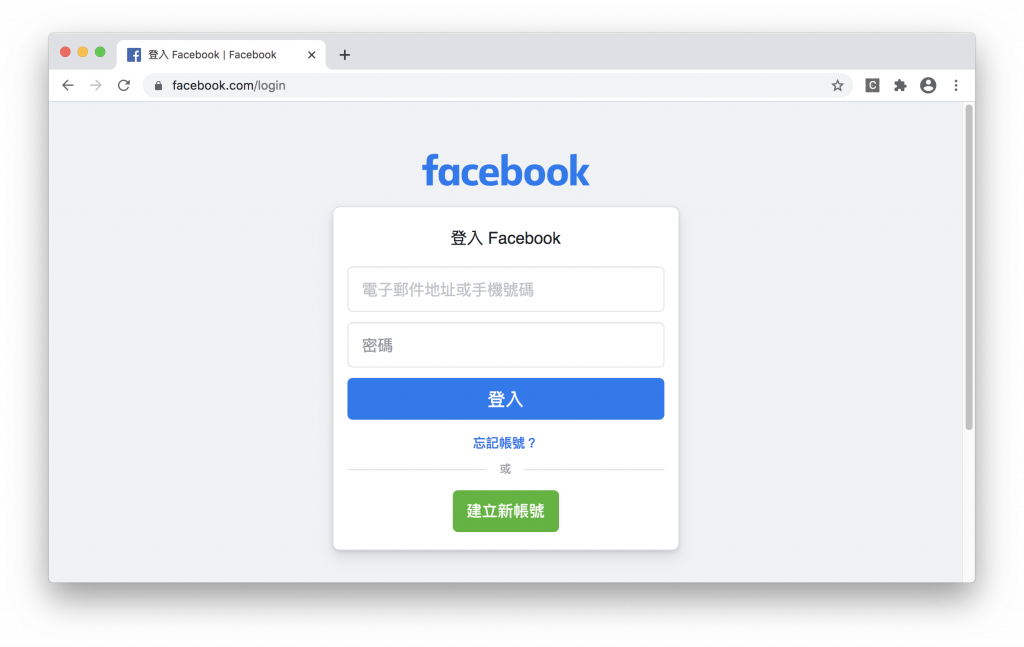
先用 chrome 無痕模式打開Facebook登入頁面

打開後的 FB 的登入畫面如下
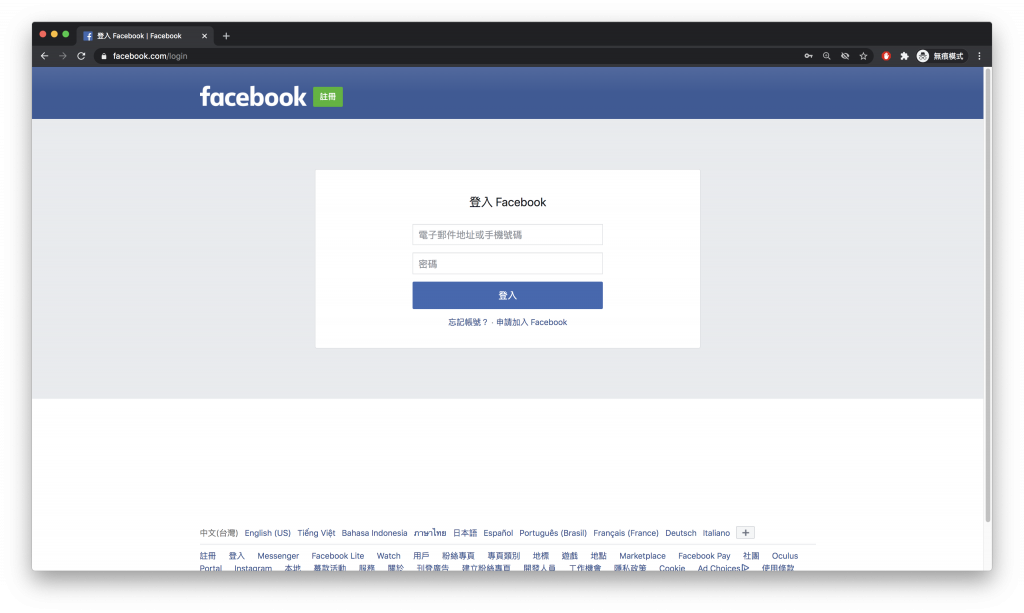
剛發完文章發現 FB 登入畫面又變惹QQ,不過操作上都一樣請勿驚慌
接下來把你平常登入FB的動作分幾個步驟,下一步要對這些操作到的元件進行結構分析:
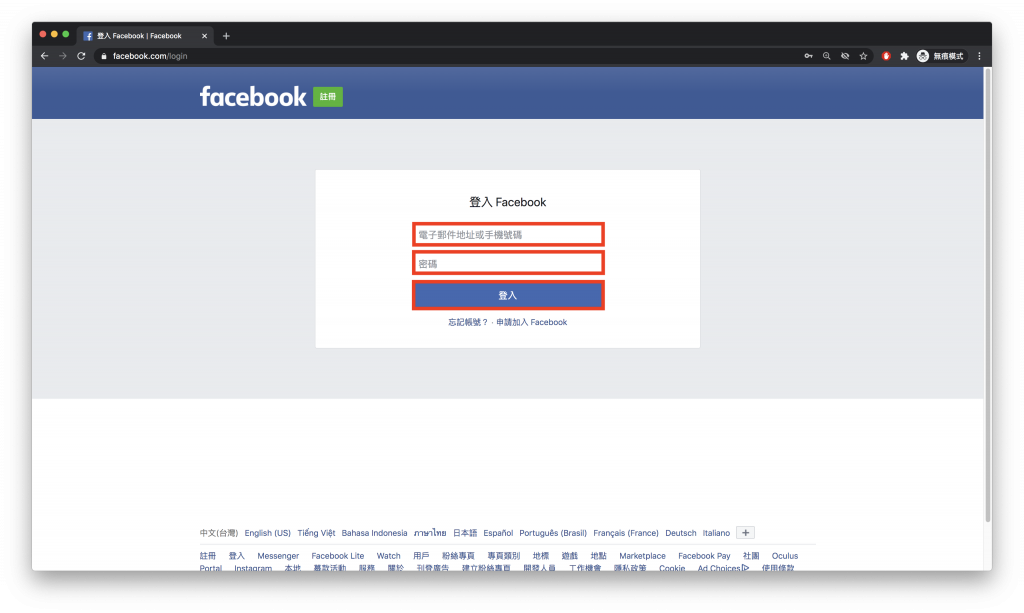
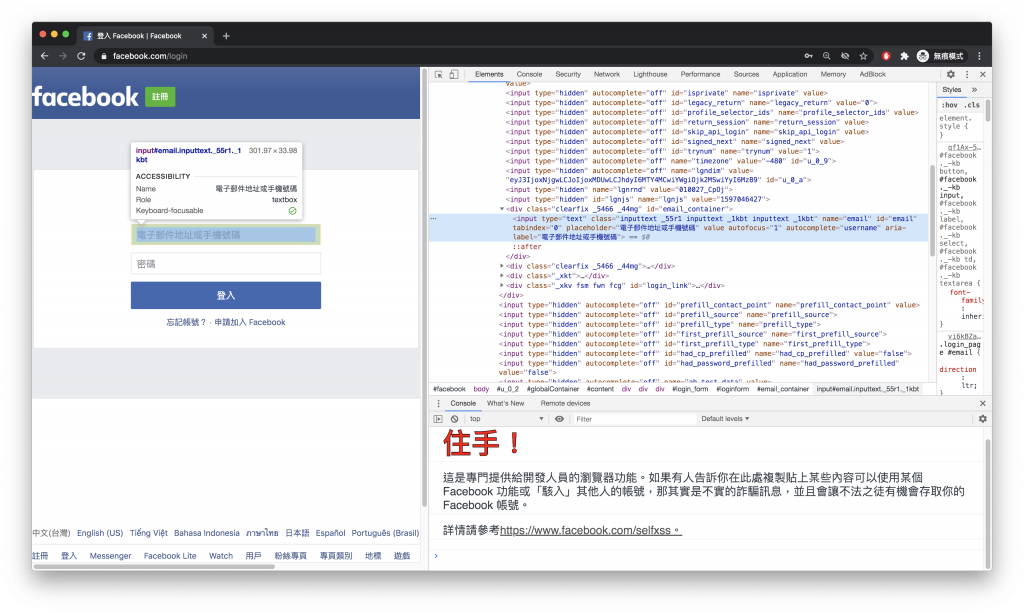
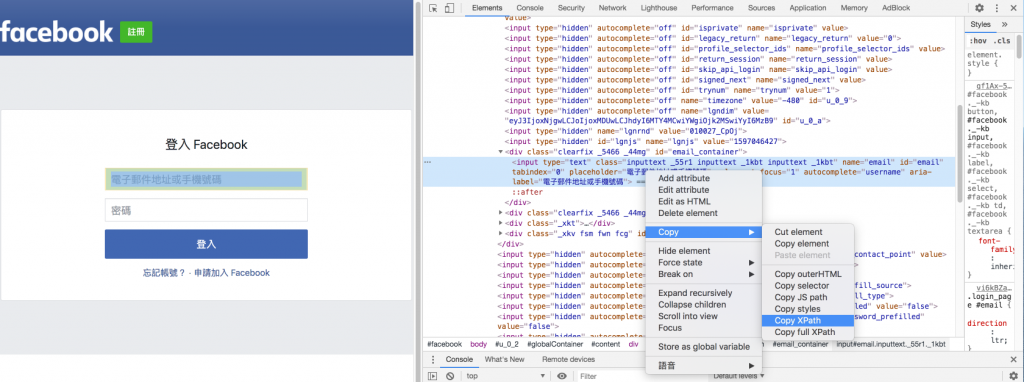
//*[@id="email"]
//*[@id="pass"]
//*[@id="loginbutton"]
// 取出想操作的元件 = 瀏覽器會等待直到路徑(//*[@id="email"])的元件顯示才回傳該元件
const fb_email_ele = await driver.wait(until.elementLocated(By.xpath(`//*[@id="email"]`)));
// 將你想要輸入的文字透過sendKeys塞入元件
fb_email_ele.sendKeys(fb_username)
// 將取出的元件使用click函式觸發點擊事件
login_elem.click()
理解關鍵程式的功能後我們來把他們組合起來吧:
#填寫自己登入FB的真實資訊(建議開小帳號來實驗,因為帳號使用太頻繁會被官方鎖住)
FB_USERNAME='fb username'
FB_PASSWORD='fb password'
require('dotenv').config(); //載入.env環境檔
//取出.env檔案填寫的FB資訊
const fb_username = process.env.FB_USERNAME
const fb_userpass = process.env.FB_PASSWORD
const webdriver = require('selenium-webdriver'), // 加入虛擬網頁套件
By = webdriver.By,//你想要透過什麼方式來抓取元件,通常使用xpath、css
until = webdriver.until;//直到抓到元件才進入下一步(可設定等待時間)
const chrome = require('selenium-webdriver/chrome');
const path = require('path');//用於處理文件路徑的小工具
const fs = require("fs");//讀取檔案用
async function loginFacebook () {
if (!checkDriver()) {
return
}
let driver = await new webdriver.Builder().forBrowser("chrome").build();
const web = 'https://www.facebook.com/login';//我們要前往FB
await driver.get(web)//在這裡要用await確保打開完網頁後才能繼續動作
//填入fb登入資訊
//使用until是要求直到網頁顯示了這個元件才能執行下一步
const fb_email_ele = await driver.
wait(until.elementLocated(By.xpath(`//*[@id="email"]`)));//找出填寫email的元件
fb_email_ele.sendKeys(fb_username)//將使用者的資訊填入
const fb_pass_ele = await driver.
wait(until.elementLocated(By.xpath(`//*[@id="pass"]`)));
fb_pass_ele.sendKeys(fb_userpass)
//抓到登入按鈕然後點擊
const login_elem = await driver.
wait(until.elementLocated(By.xpath(`//*[@id="loginbutton"]`)))
login_elem.click()
}
loginFacebook()//登入FB
 執行程式
執行程式在專案資料夾的終端機(Terminal)執行指令
yarn start
你會看到 chrome 的應用程式自動打開並且成功登入 Facebook
如果模擬器讓你成功登入 FB 可以在下方留言讓我知道喔,登入成功的瞬間有沒有充滿成就感呢?
 參考資源
參考資源免責聲明:文章技術僅抓取公開數據作爲研究,任何組織和個人不得以此技術盜取他人智慧財產、造成網站損害,否則一切后果由該組織或個人承擔。作者不承擔任何法律及連帶責任!
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、個人研究」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008



 iThome鐵人賽
iThome鐵人賽